无标题文档

常见问题
xxx.app 已损坏,无法打开,你应该将它移到废纸篓/打不开 xxx,因为它来自身份不明的开发者解决方法
方法1 开启任何来源
- 先打开 系统偏好设置 -> 安全与隐私 -> 通用 选项卡,检查是否已经启用了 任何来源 选项。
- 如果没有这个选项,复制以下面的命令:
1 | sudo spctl --master-disable |
- 重新安装文件
方法2 应用签名
安装Command Line Tools 工具
打开终端工具输入如下命令:
打开终端工具输入并执行如下命令对应用签名:
1 | sudo codesign --force --deep --sign - (应用路径) |
应用路径:打开访达(Finder),点击左侧导航栏的 应用程序,找到相关应用,将它拖进终端命令- 的后面,然后按下回车即可,注意最后一个 - 后面有一个空格。
正常情况下只有一行提示,即成功:/文件位置 : replacing existing signature
如遇如下错误:/文件位置 : replacing existing signature /文件位置 : resource fork,Finder information,or similar detritus not allowed
先在终端执行:
1 | xattr -cr /文件位置(直接将应用拖进去即可) |
然后再次执行如下指令即可:
1 | codesign --force --deep --sign - /文件位置(直接将应用拖进去即可) |
绕过公证
打开终端,输入以下命令:
1 | sudo xattr -rd com.apple.quarantine /Applications/xxxxxx.app |
将上面的 xxxxxx.app 换成App名称,比如 Sketch.appsudo xattr -rd com.apple.quarantine /Applications/Sketch.app
然后按键盘的回车键(return),输入密码,再按回车键,完成。
来自: Mac:常见问题 - BLOG
此外FlatList还可以方便地渲染行间分隔线,支持多列布局,无限滚动加载等等。
ScrollView和FlatList应该如何选择?ScrollView 会简单粗暴地把所有子元素一次性全部渲染出来。其原理浅显易懂,使用上自然也最简单。然而这样简单的渲染逻辑自然带来了性能上的不足。想象一下你有一个特别长的列表需要显示,可能有好几屏的高度。创建和渲染那些屏幕以外的 JS 组件和原生视图,显然对于渲染性能和内存占用都是一种极大的拖累和浪费。
这就是为什么我们还有专门的FlatList组件。FlatList会惰性渲染子元素,只在它们将要出现在屏幕中时开始渲染。这种惰性渲染逻辑要复杂很多,因而 API 在使用上也更为繁琐。除非你要渲染的数据特别少,否则你都应该尽量使用FlatList,哪怕它们用起来更麻烦。
开发配置
iTerm2
没有一个好看的终端怎么行
1 | brew install --cask iterm2 |
终端美化
Starship
安装
1 | brew install starship |
1 | echo 'eval "$(starship init zsh)"' >> ~/.zshrc |
配置文件
1 | mkdir -p ~/.config |
卸载sharship
- 删除 shell 配置中
~/.zshrc
用于初始化 Starship 的所有行 - 删除 Starship
Kitty
迅速、轻量化的终端
1 | brew install --cask kitty |
Tmux
安装
终端复用神器
1 | brew install tmux |
教程
Tmux 使用教程- 阮一峰的网络日志
Tmux使用手册
配置文件
1 | nano ~/.tmux.conf |
1 | #tmux attach 如果无分离终端则新建 |
1 | mkdir ~/.tmux |
1 | selectp -t 0 # select the first (0) pane |
完成后
之后使用的话,在终端输入tmux
然后 Ctrl + B 再按 Shift + V
就可以分屏了
常用命令
最大化
复制模式 q退出
窗口列表
切换窗口
会话列表
挂起
Git
1 | # 配置邮箱 |
Python
在调试Python的时候可能遇到不同的环境问题,在这里先使用pyenv进行本地环境配置,后面如果做机器学习、深度学习等使用conda虚拟环境配置
1 | brew install pyenv |
配置shell环境
1 | echo 'eval "$(pyenv init -)"' >> ~/.zshrc |
查看可安装的版本
安装与卸载
查看已安装的版本
1 | #当前版本 |
版本切换
1 | # shell 会话设置 只影响当前的shell会话 |
注意pyenv 的 global、local、shell 的优先级关系是:shell > local > global
JAVA
JDK8
https://www.123pan.com/s/L9uDVv-QQu7H.html
JDK11
https://www.123pan.com/s/L9uDVv-9Qu7H.html
JDK17
下载安装之后
再安装jenv便于切换环境
1 | brew instal jenv |
配置zshrc环境
1 | echo 'export PATH="$HOME/.jenv/bin:$PATH"' >> ~/.zshrc |
安装完成后
1 | #查看当前的 Java 版本 |
Docker
1 | brew install --cask docker |
OrbStack
OrbStack 是一种在 macOS 上运行 Docker 容器和 Linux 机器的快速、轻便且简单的方法。可以将其视为强大的 WSL 和 Docker Desktop 替代方案,全部集成在一个易于使用的应用程序中
1 | brew install orbstack |
Docker切换OrbStack
1 | docker context use orbstack |
在设置中可以进行换源
1 | { |
Parallels Desktop
Mac上性能最好的虚拟化工具
UTM
UTM 是一个功能齐全的系统模拟器和虚拟机主机,适用于 iOS 和 macOS。它基于 QEMU。所以可以模拟x86、ARM64 和 RISC-V。
1 | brew install --cask utm |
Vulnhub
kali攻击机上官网下载iso文件导入即可
官网下载
然后到vulnhub查找自己想要练习的靶机,并下载ova
vulnhub vulnhub国内镜像
1 | cd Downloads |
解压完成后安装一下qemu
1 | brew install qemu |
转换成qcow2格式
1 | qemu-img convert -O qcow2 xxx-disk001.vmdk xxx.qcow2 |
打开UTM,选择左上角➕,新建
选择模拟->其他->勾选跳过ISO启动->选择内存等->继续->填写名字->保存
在主页面能看到新建的机器->右击编辑->选择QEMU->取消勾选UEFI启动
右击IDE Drive删除
再点击驱动器下方的新建->导入->选择刚刚生成的qcow2文件即可
x86
在网上下载你想要模拟的x86系统的iso文件
打开UTM->左上角➕->选择模拟->linux(或者windows)->调整内存->驱动器大小->名字->完成
之后就可以正常打开使用了
VirtualBox
Virtualbox是一个开源的虚拟机工具
可以在官网下载安装
官网下载
Virtualbox更加适用于打靶机的情况,比如hackmyvm靶场 中大部分的靶机都是适配Virtualbox的
Vmware Fusion
Vmware是除了PD以外非常优秀的虚拟机工具,如果觉得PD收费太高,那么可以选择Vmware
官网下载
4C21U-2KK9Q-M8130-4V2QH-CF810
Firefox
开源浏览器
1 | brew install --cask firefox |
Arc
非常好看的浏览器,垂直标签栏能更好的保存网站分类
1 | brew install --cask arc |
注意需要加入愿望单,获取名额
Electerm
支持ssh/sftp的客户端
支持github,gitee同步
1 | brew install --cask electerm |
Insomnia
一个用于GraphQL、REST、WebSockets、SSE和gRPC的开源、跨平台API客户端
1 | brew install --cask insomnia |
Vscode
1 | brew install --cask visual-studio-code |
Miniconda
安装
1 | curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh |
在安装的最后会出现
1 | Do you wish the installer to initialize Miniconda3 by running conda init? [yes|no] |
输入yes
此时安装包会向当前 SHELL 的配置文件(~/.zshrc)中写入 conda 初始化语句
查看conda版本,检查是否安装成功
配置
取消激活base环境
因为我们之前已经配置了本地python环境,为了区分用途[pyenv管理的python用于python开发等,conda用于机器学习、深度学习等]
以上是我个人的习惯,如果只有单方面需求,使用对应的python配置方法即可
安装Miniconda 后,打开终端默认会激活 base 环境
所以通过命令取消掉
1 | conda config --set auto_activate_base False |
想要在终端激活conda中的虚拟环境的时候
1 | conda activate base[虚拟环境名] |
想要恢复默认激活base环境
1 | conda config --set auto_activate_base True |
conda-forge
conda-forge 是一个由社区维护的大量 Python 包的通道。 为 conda 增加 conda-forge 通道,可以安装更多的软件包
1 | conda config --add channels conda-forge |
设置通道优先级为 strict。当一个包同时位于 conda-forge 和 main 通道时,总是使用 conda-forge 提供的包
1 | conda config --set channel_priority true |
显示通道 URL
1 | conda config --set show_channel_urls true |
conda换源
1 | conda config --add default_channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main |
设置 conda 使用更快的 libmamab solver
1 | conda install -n base conda-libmamba-solver |
conda虚拟环境
创建虚拟环境
1 | conda create -n py38 python=3.8 |
激活虚拟环境
1 | conda activate py38 |
查看已创建的虚拟环境
1 | conda env list |
退出当前环境
1 | deactivate 环境名字 |
删除环境
1 | conda remove -n 环境名字 --all |
删除环境钟的某个包
1 | conda remove -n 环境名字 包名 |
TensorFlow
安装
1 | conda install -c apple tensorflow-deps |
测试
1 | conda activate py38 |
Pytorch
安装
Anaconda
1 | conda install pytorch torchvision torchaudio -c pytorch-nightly |
pip
1 | pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu |
测试
1 | import torch |
The output should show:
1 | tensor([1.], device='mps:0') |
安装一些常用的库
1 | pip install pandas matplotlib glob2 tqdm opencv-python scipy scikit-learn mlx |
Adobe全家桶
https://www.yuque.com/yihulaojiu-gsfg9/zz2qv5/vixkf6
MATLAB
官方文档
安装Amazon Corretto 8
对于 Apple silicon Mac 上的 MATLAB,MathWorks 仅支持 Amazon Corretto 8 附带的 Java 8 JRE。
下载Amazon Corretto 8
官网下载链接🔗
https://www.mathworks.com/downloads/web_downloads/
Pinokio
在AI蓬勃发展的阶段,有许多AI应用出现,但配置的过程对于很多人来说比较复杂Pinokio就可以一键安装LobeChat,Stable Diffusion web UI等等
下载链接

LM Studio
Ollama
来自: Mac:开发配置 - BLOG
日常软件
前置工作
允许安装任意来源的 App
1 | sudo spctl --master-disable |
然后前往系统偏好设置👉安全性与隐私👉点击左下角的小锁

安装 Xcode Command Line Tools
工具依赖
1 | xcode-select --install |
HomeBrew
安装
1 | /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" |
国内环境安装命令
1 | /bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/install.sh)" |
❗注意
如果命令执行中卡在下面信息: (来源于https://brew.idayer.com/guide/start/#part3)
==> Tapping homebrew/core
Cloning into ‘/usr/local/Homebrew/Library/Taps/homebrew/homebrew-core’…Control + C中断脚本执行如下命令:
1 | cd "$(brew --repo)/Library/Taps/" |
然后再执行
1 | /bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/install.sh)" |
安装完成后根据提示,运行下面的命令
1 | echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zprofile |
安装一下cask便于后面软件的安装
1 | brew install cask |
常用命令
更新Homebrew
搜索相关包
卸载软件
查看已安装的软件
卸载Homebrew
官方脚本
1 | /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/uninstall.sh)" |
国内脚本
1 | /bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/uninstall.sh)" |
软件商店
防火墙
首先要安装的就是防火墙,Mac自带的防火墙只能防御进入Mac的流量,但是遇到流氓软件向服务器上传我们的隐私数据就防御不了。同时也可以过滤广告哦。
我们可以选择两个软件,二选一即可
Little Snitch(许可证一次收费)
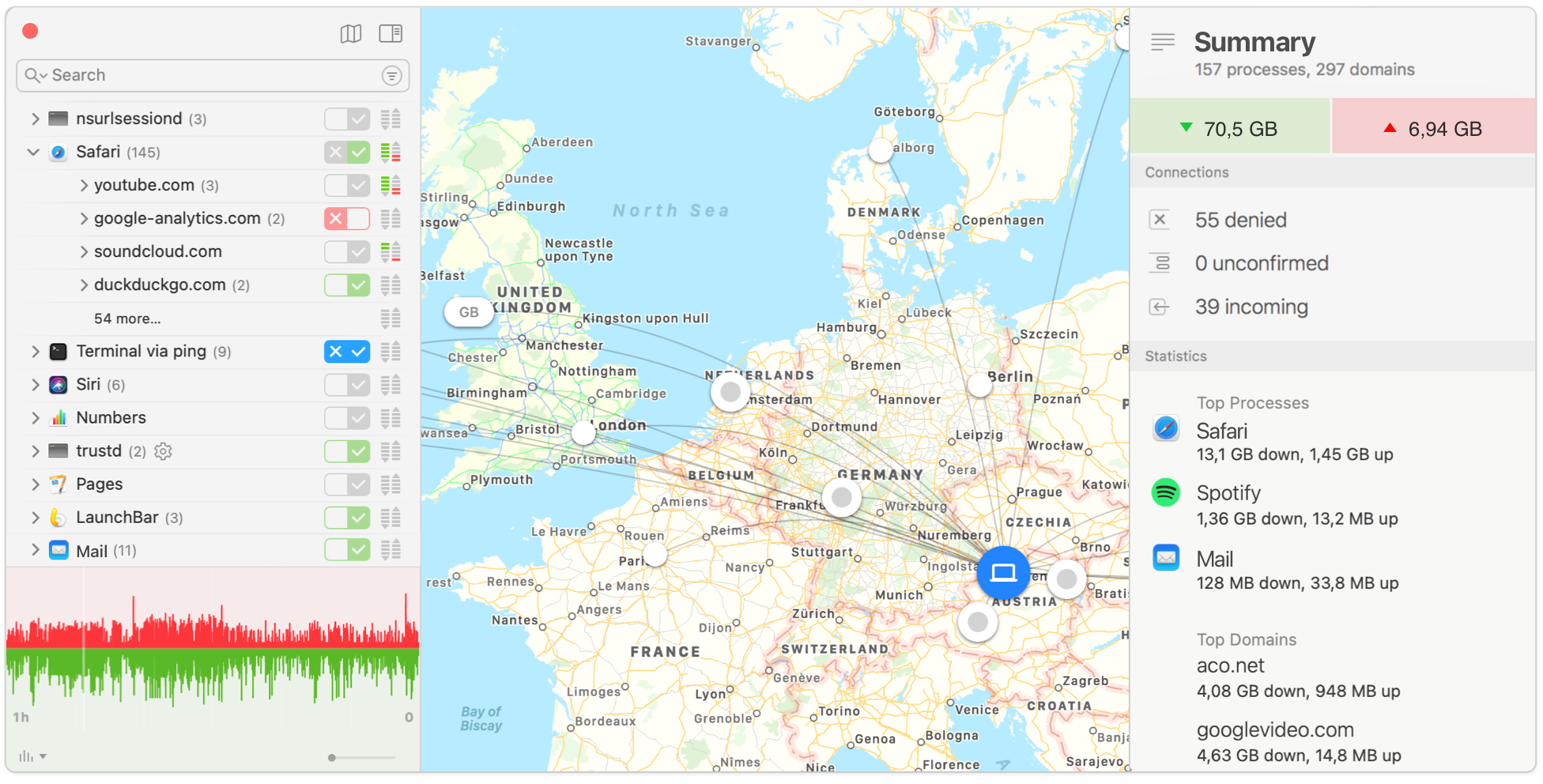
许可证可以在淘宝进行购买,按需购入
LuLu(开源,免费)
LuLu是一个开源的防火墙工具
安装也很简单
1 | brew install --cask lulu |
保持默认选项
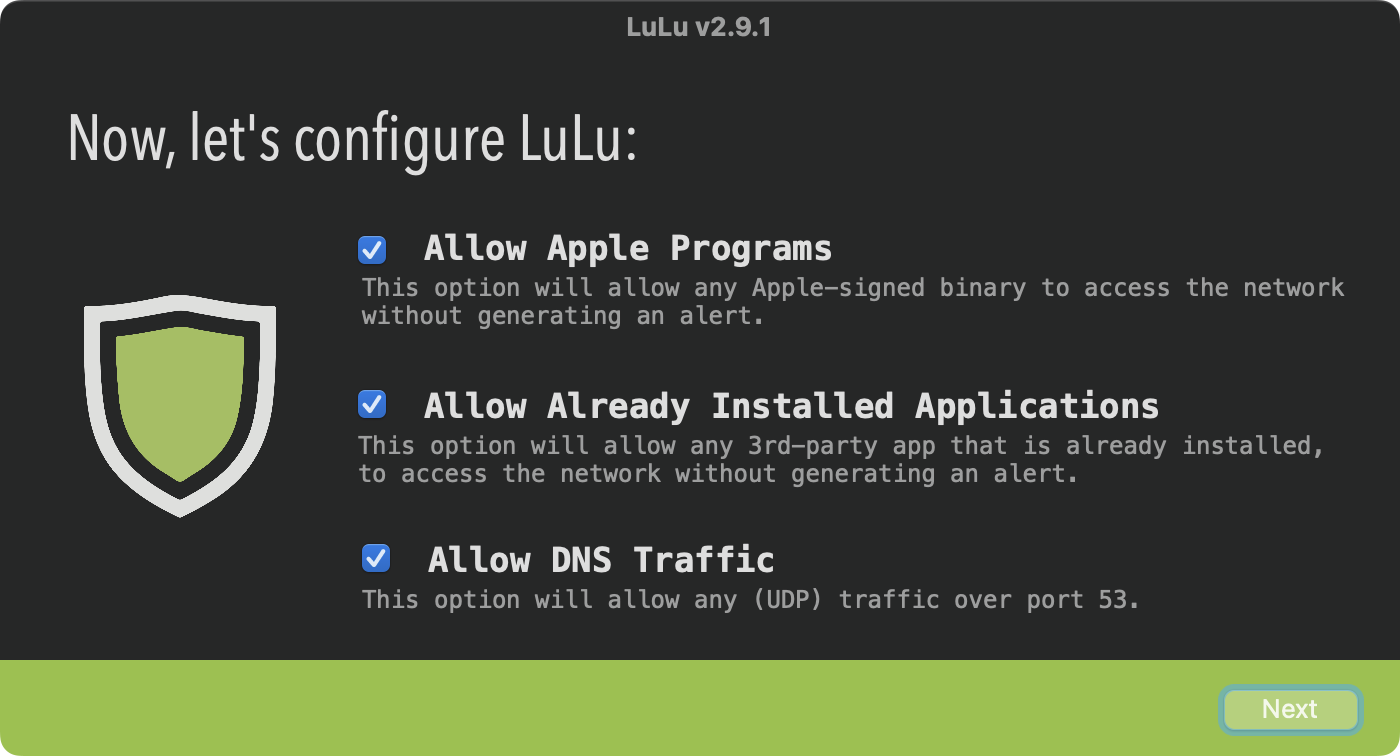
有程序发起请求时,会跳出弹窗,我们只需要选择放行或者阻止即可,设置过一次或者配置好规则就可以一劳永逸
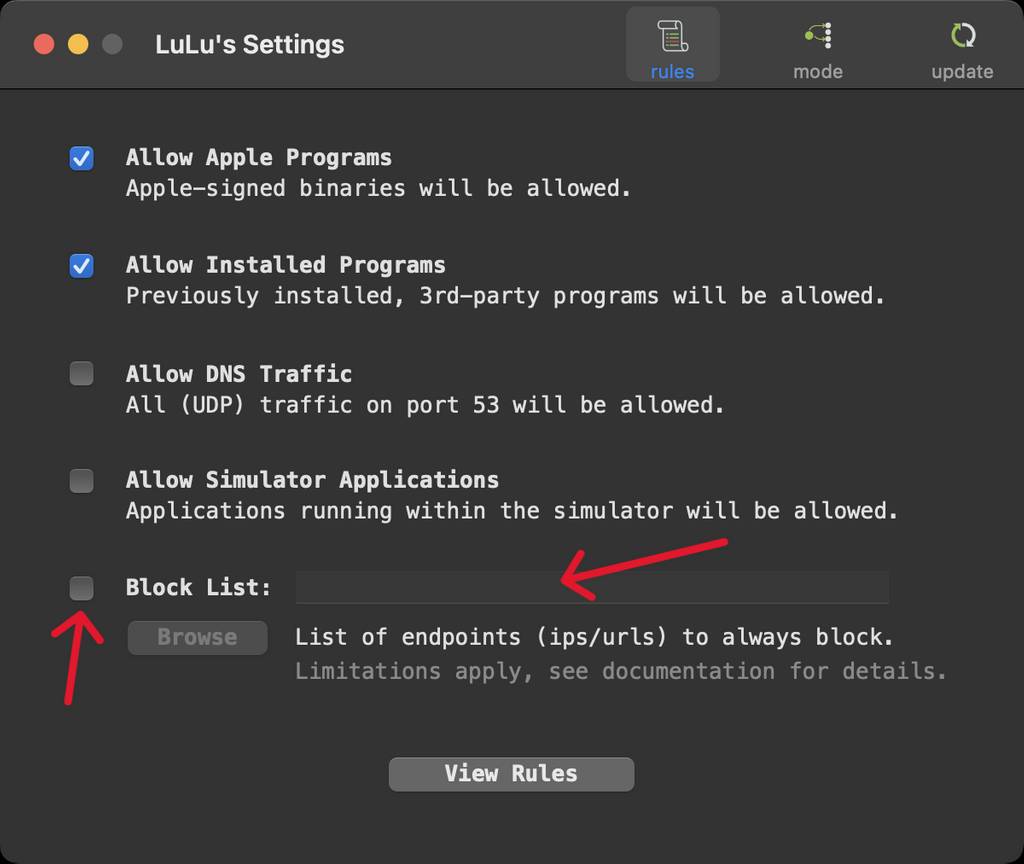
附上常见的阻止🚫规则 blockyouxlist ,勾选然后粘贴链接即可
1Password
非常值得入手的密码管理工具,只需要记住一个密码就可以自动保存、保存填写网站、SSH密钥、加密钱包等密码
淘宝购入年费会员也不贵,安全性也不错,全平台通用
1 | brew install --cask 1password |
Raycast
Raycast是一个启动器,可以高效打开文件、软件、网站并执行各种便捷操作,可以代替Mac 自带的 「焦点(Spotlight)」
同样brew安装
1 | brew install --cask raycast |
也可以官网下载dmg文件
官网下载地址
教程
插件
以下是一些推荐的插件
1password
chatgpt
Chatgpt免费API申请

Raycast-G4F (GPT4Free)
免费使用GPT4,Llama-3等等,无需API密钥

Vscode
Kill Process
🔋Battery(AlDente Pro免费平替)
一个开源的电池保护工具
AlDente Pro免费平替🆓

1 | brew install --cask battery |
使用方法
电池充到80停止
PrettyClean
好用的 macOS 磁盘清理工具
https://www.prettyclean.cc/zh
点击下载
Keka
压缩解压工具
1 | brew install --cask keka |
Lux
Youtube、Bilibili视频下载器
https://github.com/iawia002/lux
1 | brew install lux |
下载单个视频
1 | lux "https://www.youtube.com/watch?v=dQw4w9WgXcQ" |
-i 选项可显示所有可用的视频质量,无需下载。
1 | lux -i "https://www.youtube.com/watch?v=dQw4w9WgXcQ" |
使用 lux -f stream “URL” 下载 -i 选项输出中列出的特定数据流。
下载播放列表
-p 选项下载的是整个播放列表,而不是单个视频。
1 | lux -i -p "https://www.bilibili.com/bangumi/play/ep198061" |
可以使用 -start 、 -end 或 -items 选项来指定列表的下载范围:
1 | -start |
下载多个视频
1 | lux -i "https://www.bilibili.com/video/av21877586" "https://www.bilibili.com/video/av21990740" |
更多信息请查看https://github.com/iawia002/lux
IINA
视频播放器
1 | brew install --cask iina |
Vidhub
可挂载阿里云盘、百度网盘、SMB、WebDAV等资源,并支持直连Emby、Jellyfin、Plex媒体库。
可以播放4K视频,HDR效果目前不如Infuse。
免费🆓!还能生成精美的海报墙,要什么自行车🚲
App Store下载
XPTV
美区软件,支持添加阿里云盘、夸克网盘,可以添加tvbox的源!,IPTV源
App Store下载
shottr
纯净的截屏工具
长截图,ocr,智能打码,贴图,取色等功能
1 | brew install --cask shottr |
ishot
国产多功能截屏工具
长截图,录音,录屏,ocr,贴图,取色等功能
官方下载
QuickRecorder
多功能、轻量化、高性能的 macOS 屏幕录制工具
- 使用 SwiftUI 编写, 体积小巧轻量化. 软件大小仅 4MB 左右, 无任何累赘功能.
- 支持窗口录制, App 录制等模式; 支持窗口声音内录, 鼠标高亮, 隐藏桌面文件等功能.
- QuickRecorder 启动后直接显示主功能面板, 关闭后可以点击 Dock 栏图标再次呼出.
1 | brew install lihaoyun6/tap/quickrecorder |
Bob or TTime
两款都是优秀的翻译软件,可以划词翻译和截图翻译
Bob TTime
Bob是老牌mac工具,目前在Appstore可以下载,而github版本已停止维护
可以下载免费的bob插件使用

TTime是新晋的开源工具,可以自己配置ocr和翻译的api,可以申请大厂的api接口,都有免费额度,足够个人使用了
Ice
菜单栏管理工具
只需 Command + 拖动菜单栏项目 即可重新排列
1 | brew install jordanbaird-ice |
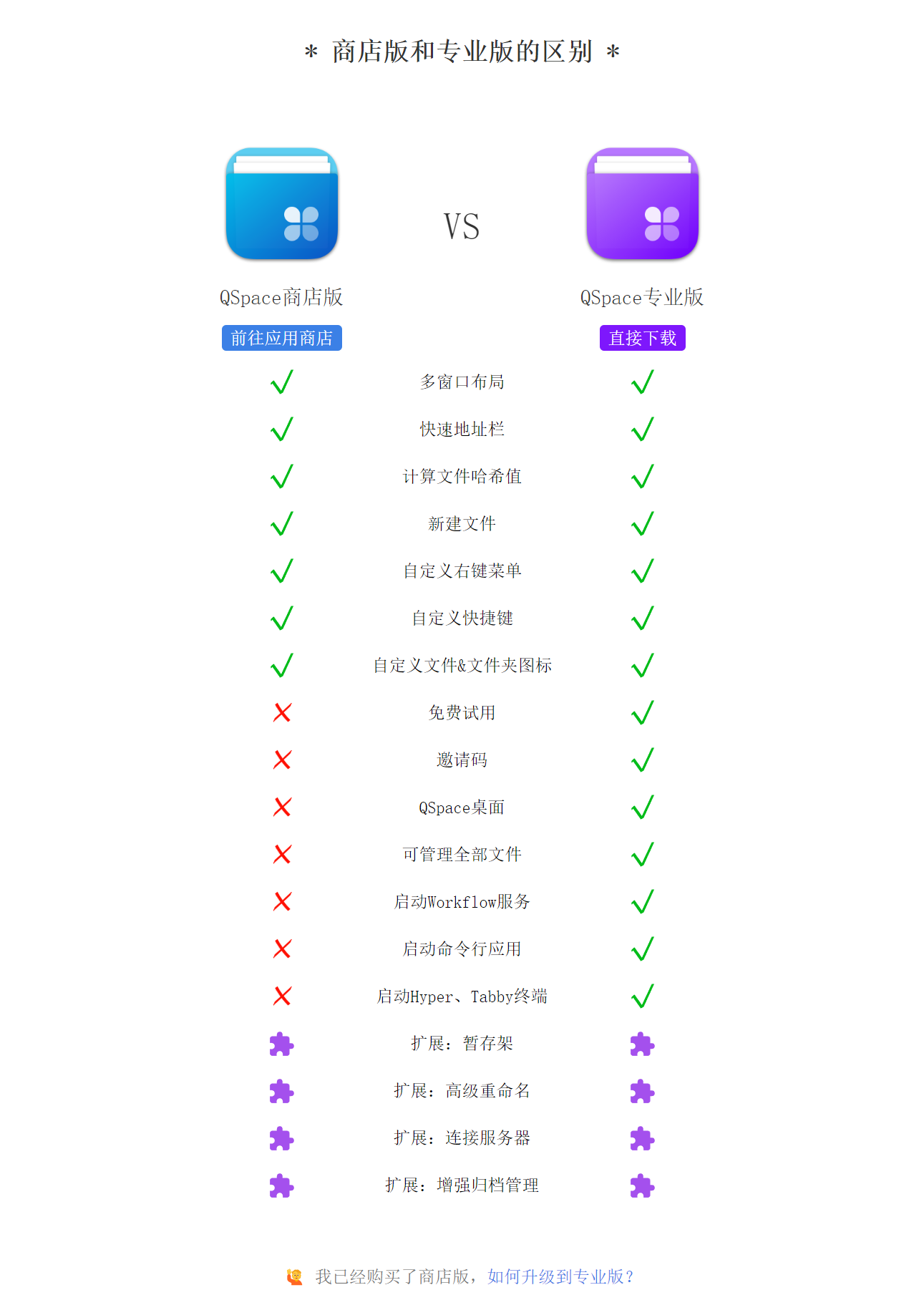
Qspace
一款多窗口布局的文件管理工具
官方下载
免费版与专业版的区别
Rectangle
快捷键分屏
1 | brew install --cask rectangle |
Obsidian
优秀的笔记工具
可以更改主题,安装各种插件
同步可以用github
官网下载
KeyboardHolder
有些时候我们会遇到总是频繁切换中英文输入法,或者标点的场景
使用这款工具就可以记住场景,自动切换
1 | brew install --cask keyboardholder |
Mac Mouse Fix
1 | brew install mac-mouse-fix |
Motrix
开源的下载器,支持HTTP, FTP, BitTorrent, Magnet等
1 | brew install --cask motrix |
PDF Expert
Mac上非常优秀的Pdf编辑、查看、管理工具
官网
PDFGear
免费的PDF编辑、阅读工具
自带AI阅读PDF,OCR识别
官网
Wechat微信
Telegram
1 | brew install --cask telegram |
Discord
1 | brew install --cask discord |
NetNewsWire
RSS阅读器
1 | brew install --cask netnewswire |
鼠须管Squirrel输入法
Rime输入法
开源,高度自定义
1 | brew install --cask squirrel |
配置
自动化配置脚本👉https://github.com/Mark24Code/rime-auto-deploy/tree/main
- 安装依赖
ruby3
1 | brew install ruby |
- 执行下面的代码
1 | git clone --depth=1 https://github.com/Mark24Code/rime-auto-deploy.git --branch latest |
来自: Mac:日常软件 - BLOG
系统设置
基本设置
取消 4 位数密码限制
1 | pwpolicy -clearaccountpolicies |
程序坞自动隐藏加速
1 | # 设置启动坞动画时间设置为 0.5 秒 |
启动台自定义行和列
1 | # 设置列数 |
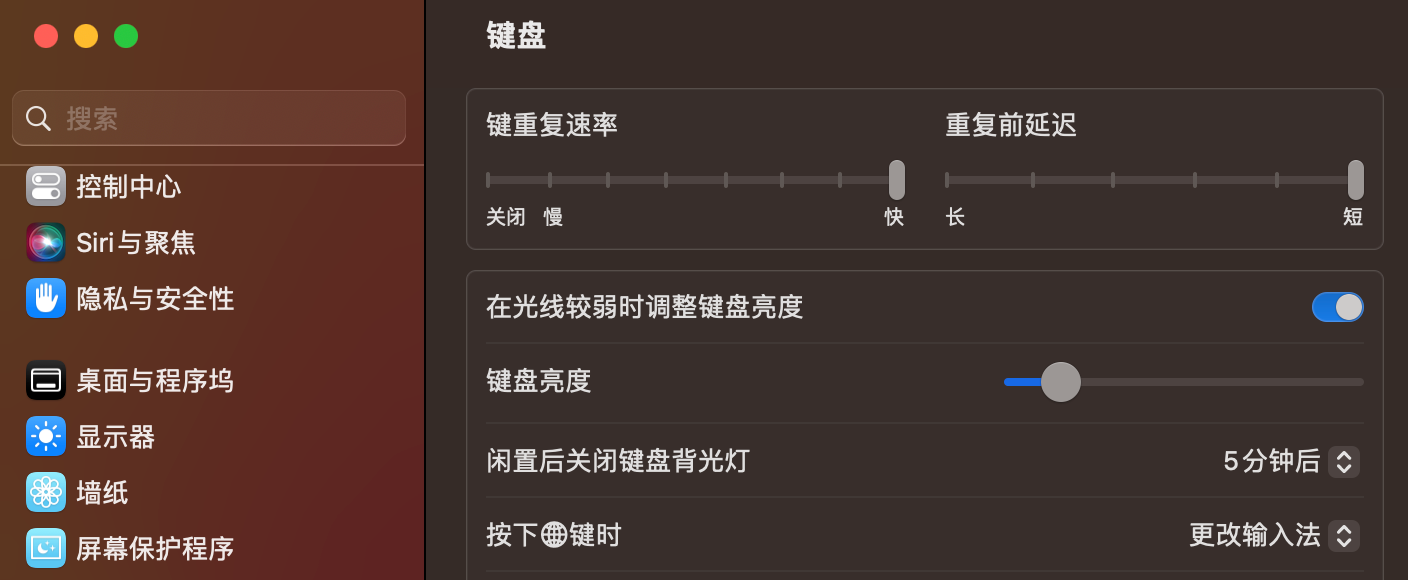
键盘设置
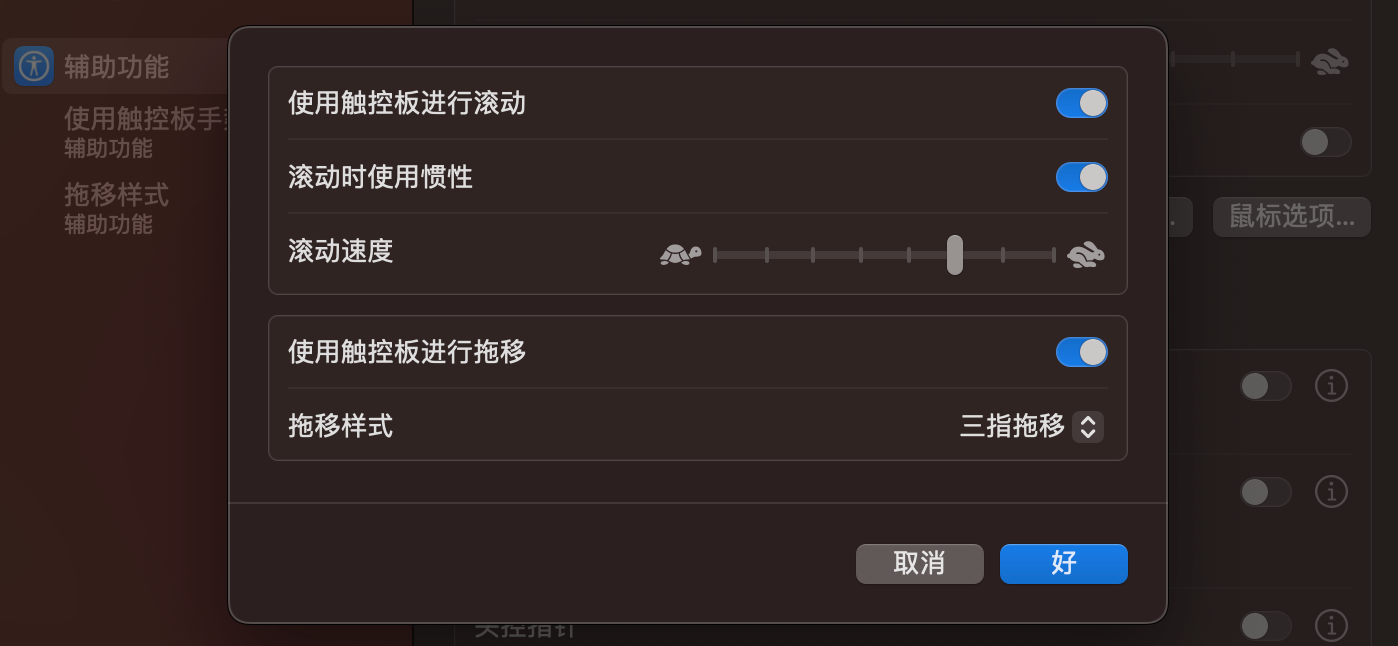
触控板设置
光标响应
打开系统偏好设置->触控板->光标与点按
勾选✔轻点来点按
跟踪速度移动到最快
三指拖移
打开系统偏好设置->辅助功能->指针控制
来自: Mac:系统设置 - BLOG
Kubernetes Pod 是由一个或多个为了管理和联网而绑定在一起的容器构成的组。本教程中的 Pod 只有一个容器。 Kubernetes Deployment 检查 Pod 的健康状况,并在 Pod 中的容器终止的情况下重新启动新的容器。 Deployment 是管理 Pod 创建和扩展的推荐方法。
kube-apiserver
API 服务器是 Kubernetes 控制平面的组件, 该组件负责公开了 Kubernetes API,负责处理接受请求的工作。 API 服务器是 Kubernetes 控制平面的前端。
Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平扩缩,也就是说,它可通过部署多个实例来进行扩缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
@Resource 和 @Autowired
@Resource 和 @Autowired 都用于依赖注入,但它们有一些重要的区别。以下是它们的主要比较:
- 来源:
@Resource是 Java EE 标准的一部分(javax.annotation 包)@Autowired是 Spring 框架特有的注解
- 默认匹配策略:
@Resource默认按名称匹配,如果找不到再按类型匹配@Autowired默认按类型匹配
- 指定名称:
@Resource可以通过name属性指定 bean 名称:@Resource(name="beanName")@Autowired需要配合@Qualifier注解来指定 bean 名称
- 适用范围:
@Resource可用于字段、setter 方法和构造函数@Autowired可用于构造函数、字段、setter 方法和普通方法
- 处理方式:
@Resource先按名称匹配,找不到再按类型匹配@Autowired先按类型匹配,如果找到多个再按名称匹配
- 兼容性:
@Resource在 Java EE 环境中更通用,可以在不同的 Java EE 容器中使用@Autowired是 Spring 特有的,与 Spring 容器紧密集成
- 功能扩展:
@Autowired提供了更多的扩展功能,如required属性可以指定是否必须注入
- 泛型支持:
@Autowired对泛型类型的注入支持更好
选择使用 @Resource 还是 @Autowired 主要取决于以下因素:
- 如果您的项目严格遵循 Java EE 标准,使用
@Resource可能更合适。 - 如果您主要使用 Spring 框架,并需要其提供的额外功能,
@Autowired可能更合适。 - 如果您希望默认按名称注入,
@Resource更直接。 - 如果您的项目可能需要在不同的 Java EE 容器间迁移,
@Resource可能是更好的选择。
在您的 JwtUtils 类中,使用 @Resource 或 @Autowired 来注入 StringRedisTemplate 都是可行的。选择 @Resource 可能是为了保持与 Java EE 标准的一致性,或者是为了利用其默认按名称匹配的特性。
@Component 和@Bean
主要区别:
- 使用方式:
- @Component 用于类,自动扫描。
- @Bean 用于方法,手动声明。
- 控制力:
- @Component 让 Spring 全权负责 bean 的创建和管理。
- @Bean 允许您完全控制 bean 的实例化过程。
- 适用范围:
- @Component 主要用于您自己的类。
- @Bean 可以用于任何类,包括第三方库的类。
- 配置灵活性:
- @Component 配置相对简单,主要依赖于自动装配。
- @Bean 允许更复杂的配置,可以在创建 bean 时执行任意代码。
- 命名:
- @Component 默认使用类名(首字母小写)作为 bean 名称。
- @Bean 默认使用方法名作为 bean 名称,但可以通过 @Bean(name = “customName”) 自定义。
在您的 JwtUtils 类中使用 @Component 是合适的,因为:
- 它是您自己编写的类。
- 可能不需要复杂的初始化逻辑。
- 您希望 Spring 自动管理其生命周期和依赖注入。
如果 JwtUtils 需要复杂的初始化或者您想更精细地控制其创建过程,那么使用 @Bean 在配置类中声明可能会更合适。
@Service 和 @Component
@Service 和 @Component 都是 Spring 框架中的注解,它们有一些相似之处,但也有一些细微的区别。让我为您解释这两个注解的作用和区别:
- @Component 的作用:
- 这是一个通用的 Spring 管理的组件注解。
- 它告诉 Spring 框架,被注解的类是一个组件,应该由 Spring 容器管理。
- Spring 会自动检测这些带有 @Component 注解的类,并将它们注册为 Spring beans。
- @Service 的作用:
- @Service 是 @Component 的一个特化。
- 它主要用于标注业务逻辑层的组件,即 Service 层。
- 从功能上讲,@Service 和 @Component 做的是同样的事情。
- 主要区别:
- 语义差异:@Service 更具体地表明这个类是一个服务类,通常用于业务逻辑处理。
- 分层清晰:使用 @Service 可以让代码结构更清晰,表明这是服务层的组件。
- 未来扩展:Spring 可能在未来为 @Service 添加特定的功能或行为。
- 使用场景:
- @Component:通常用于那些不好归类的通用组件。
- @Service:用于标注服务层组件,如业务逻辑处理类。
- 其他相关注解:
- @Repository:用于数据访问层(DAO 层)。
- @Controller:用于表现层(如 Spring MVC 的控制器)。
- 示例:
1 |
|
总的来说,虽然 @Service 和 @Component 在当前的 Spring 版本中功能基本相同,但使用 @Service 可以更好地表达类的意图和职责。这有助于提高代码的可读性和可维护性,特别是在大型项目中。选择使用哪个注解主要取决于您的类的具体用途和您团队的编码规范。
@ComponentScan
@ComponentScan 注解用于扫描指定包及其子包中的所有带有特定注解的类,这些注解包括但不限于:
- @Component
- @Service
- @Repository
- @Controller
- @RestController
- @Configuration
因此,@ComponentScan(“org.licensecore.filter”) 会扫描 org.licensecore.filter 包及其子包中所有带有上述注解的类,而不仅仅是 @Configuration 或 @Component 注解的类。
具体来说:
- 它会扫描并注册所有带 @Component 注解的类(包括 @Service、@Repository 等,因为这些都是 @Component 的特化形式)。
- 它也会扫描并处理所有带 @Configuration 注解的类。
- 对于 @Configuration 类,它还会处理这些类中定义的 @Bean 方法。
VO 通常是 “Value Object”
VO 通常是 “Value Object”(值对象)的缩写。在软件开发中,特别是在 Java 项目中,VO 是一种常见的设计模式和命名约定。让我解释一下 VO 的概念和用途:
- VO 的定义:
VO 是一个纯粹的数据载体,用于在不同层之间传输数据。它通常不包含业务逻辑,只有简单的 getter 和 setter 方法。 - VO 的主要用途:
- 数据传输:在应用程序的不同层(如表示层和服务层)之间传递数据。
- 数据封装:将相关的数据字段组合在一起,形成一个有意义的对象。
- 视图呈现:特别适用于向前端或 UI 层传递数据,只包含需要显示的信息。
- VO 与其他概念的区别:
- DTO(Data Transfer Object):VO 和 DTO 很相似,有时候这两个术语会互换使用。但严格来说,DTO 更多用于远程调用场景。
- Entity:实体类通常与数据库表直接对应,而 VO 则是根据视图或接口的需求定制的。
- 在您的代码中:
AuthorizeVO可能是用于封装授权信息的值对象。它包含了用户名、角色、令牌和过期时间等授权相关的信息,这些信息可能需要返回给客户端或在应用程序的不同部分之间传递。 - 使用 VO 的好处:
- 数据隔离:可以隐藏不需要暴露的内部细节。
- 灵活性:可以根据不同的视图需求创建不同的 VO。
- 安全性:可以控制哪些数据可以传输,避免敏感信息泄露。
总之,VO 是一种用于数据传输和展示的对象,它帮助我们组织和封装数据,使代码更加清晰和易于维护。在您的项目中,AuthorizeVO 很可能用于在授权过程中传递和展示相关的授权信息。
@Controller、@RestController 和 @ResponseBody
您提出了一个很好的问题。@Controller、@RestController 和 @ResponseBody 这三个注解在 Spring MVC 中有着不同的用途和行为。让我为您详细解释它们的区别:
@Controller@ResponseBody@RestController
1. @Controller
@Controller是一个专门用于标识控制器类的注解。- 它是
@Component的一个特化,允许通过类路径扫描自动检测实现类。 - 使用
@Controller注解的类,其方法默认返回一个视图名,Spring 会试图将这个视图名解析为实际的视图(如 JSP 页面)。 - 如果方法返回
String,Spring 会将其解释为视图名。 - 如果方法返回对象,Spring 会尝试将其解析为模型属性,并寻找一个默认视图。
示例:
1 |
|
2. @ResponseBody
@ResponseBody是一个方法级别的注解,可以用在@Controller类的方法上。- 它告诉 Spring 将方法的返回值直接写入 HTTP 响应体,而不是将其解释为视图名。
- 通常用于返回 JSON 或 XML 数据。
- Spring 使用 HTTP 消息转换器将返回值转换为 HTTP 响应体。
示例:
1 |
|
3. @RestController
@RestController是@Controller和@ResponseBody的组合注解。- 它是在 Spring 4.0 引入的,为创建 RESTful Web 服务提供便利。
- 使用
@RestController注解的类中的所有方法都默认假定为@ResponseBody。 - 它简化了 RESTful Web 服务的创建,不需要在每个方法上都添加
@ResponseBody。
示例:
1 |
|
主要区别
- 返回值处理:
@Controller:默认返回视图名。@Controller+@ResponseBody:返回序列化后的数据(如 JSON)。@RestController:默认返回序列化后的数据,相当于每个方法都加了@ResponseBody。
- 使用场景:
@Controller:适用于传统的 Spring MVC 控制器,通常用于返回视图。@ResponseBody:当在@Controller中有些方法需要返回数据而不是视图时使用。@RestController:适用于 RESTful Web 服务,所有方法都默认返回数据而不是视图。
- 代码简洁性:
@RestController使代码更简洁,不需要在每个方法上都添加@ResponseBody。
- 灵活性:
@Controller+@ResponseBody的组合提供了更大的灵活性,可以在同一个控制器中混合使用返回视图和数据的方法。
总结
- 如果您的控制器主要处理视图,使用
@Controller。 - 如果您的控制器主要提供 RESTful 服务,返回数据而不是视图,使用
@RestController。 - 如果您需要在主要返回视图的控制器中偶尔返回数据,可以在
@Controller类中的特定方法上使用@ResponseBody。
选择使用哪种注解取决于您的具体需求和应用程序的设计。在现代的 Spring 应用中,特别是在构建 RESTful 服务时,@RestController 因其简洁性和明确性而被广泛使用。
当在其他文件中导入时,可以给默认导出指定任何名称。
- 文件位置:
@/server通常是一个别名,指向src/server目录。在这个目录中,很可能有一个index.ts文件。 - 默认导出:
在src/server/index.ts文件中,Axios实例被创建并作为默认导出。这可能看起来像这样:
1 | // ... 其他导入和配置 ... |
- 导入重命名:
当在其他文件中导入时,可以给默认导出指定任何名称。所以import http from '@/server'实际上是在导入Axios实例,但将其重命名为http。 - 为什么使用
http:
使用http这个名称是一种常见做法,因为它简洁地表示了这个对象的用途 - 用于发送 HTTP 请求。 - 别名配置:
@别名通常在项目的构建配置中设置(如 Vite 或 webpack 配置文件中)。它允许使用简短的路径而不是相对路径。
要确认这一点,您可以:
- 检查
src/server/index.ts文件,确认它确实默认导出了 Axios 实例。 - 查看项目的构建配置,确认
@别名的设置。
这种方式的好处是:
- 集中管理 HTTP 客户端配置
- 在整个应用中使用一致的 HTTP 客户端实例
- 通过别名和默认导出简化导入语句
如果您想更明确地表示这一点,可以考虑在 src/server/index.ts 中这样导出:
1 | export const http = Axios |
这样,您就可以选择使用 import http from '@/server' 或 import { http } from '@/server',两者都是有效的。
跨域cors login:1 Access to XMLHttpRequest at ‘http://localhost:8080/api/auth/login' from origin ‘http://localhost:5173 ‘ has been blocked by CORS policy: Response to preflight request doesn’t pass access control check: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
使用代理。这个项目使用了代理 URL 的方式来解决前端跨域请求问题。具体实现步骤如下:
- 代理配置文件:
在config/proxy.ts中定义了不同环境的代理设置。例如,开发环境下的代理配置:
1 | development: { |
这里将 /api/ 的请求代理到 http://127.0.0.1:3060。
- Vite 配置:
在vite.config.ts中,使用server.proxy来设置代理:
1 | server: { |
这段代码根据当前模式(如开发模式)选择相应的代理配置。
- 请求路径:
在前端代码中,API 请求使用相对路径(如/api/auth/login),Vite 的开发服务器会根据代理配置将请求转发到指定的目标服务器。
通过这种方式,前端代码不需要直接访问跨域的后端服务器,而是通过本地开发服务器的代理来实现请求转发,从而解决跨域问题。
前端发送POST请求,后端数据收到为null解决方案、@RequestBody注解的详细使用、content-type决定了发送什么类型的数据
以JSON形式发送,查看后端的数据接收情况:
查看我们后端mvc的controller配置
1 | ("/books") |
很明显,我是以Book实体类来接收JSON数据,JSON数据是放在post请求body(请求体)当中的,而我们以实体类来接收当然不会接收数据。
解决方式:加@RequestBody注解来将JSON数据封装给JAVABean类型
1 | ("/books") |
这样后端便可以接收到数据了
不使用@RequestBody注解,如果是以post请求将数据放在请求头的参数中情况会是怎么样呢?
打开PostMan工具,将数据放在请求头当中
后端接收到了数据:
这种情况总结:
1、以POST请求将数据放在请求体当中,后端需要使用@RequestBody注解来对JAVABean类型数据进行封装。
2、将参数放在请求头中,会自动对数据封装,不使用@RequestBody注解也可以。
原因: 后端根据不同的Content-Type等情况,Spring-MVC会采取不同的HttpMessageConverter实现来进行信息转换解析,数据放在请求体中,Content-Type类型为application/json,数据放在请求头中,Content-Type类型为application/x-www-form-urlencoded。
谷歌浏览器也会根据Content-Type的类型不同将数据在开发者工具中显示不同,如果是json类型就会显示Request Payload,如果是form,就会显示Form Data。
上述情况分析完了,接下来看下什么情况该使用@RequestBody注解,什么情况不该使用。
@ReqestBody注解
1、第一种情况就是上面这种,前端发送数据类型为json数据,后端使用@RequestBody注解来自动对数据封装。
对于这种情况有点需要注意一下,如果是String类型而不是JAVABean类型,使用了该注解,则接受到的json数据转换为String类型,并且数据内容是json形式的字符串,看:
通过PostMan发送json数据,首先设置请求头将Content-Type类型设置为application/json类型
发送请求体
看下后端的数据:json形式的字符串
我们要使用还得把这个数据给提取出来。
首先导入对应jar包
1 | <!-- JSONObject对象依赖的jar包 --> |
进行数据提取
1 |
|
很明显,繁琐,所以这种一个数据我们还是使用get方式将参数放在url中合适。
2、前端发送数据类型为form-data类型,后端不使用@RequestBody注解。
使用ajax发送post请求时数据都默认为json类型,如果是表单设置post请求,发送到后端,默认为form-data类型,前面说的数据放在请求头中,就是该情况,后端会自动对数据进行封装,无论是JAVABean类型还是基本类型,当然如果数据较多还是放在请求体中比较好。
有状态无状态jwt认证
登录阶段:
前端发送用户名和密码到后端的登录接口。
后端验证用户名和密码。
如果验证成功,后端生成一个 JWT token。
后端将 token 返回给前端。
前端存储 token:
前端收到 token 后,通常会将其存储在 localStorage、sessionStorage 或 cookie 中。
后续请求:
对于需要认证的请求,前端会在每个请求的 header 中加入 token,通常是在 Authorization 头中。
例如:Authorization: Bearer
后端验证 token:
后端接收到请求后,会验证 token 的有效性。
如果 token 有效,后端会处理请求并返回相应的数据。
如果 token 无效或过期,后端会返回一个认证错误。
- token 刷新:
JWT 通常有一个过期时间。
在 token 过期之前,前端可能需要请求一个新的 token。
有些系统会使用刷新 token 的机制来获取新的访问 token。
- 登出:
在 JWT 机制中,登出通常是前端的操作。
前端删除存储的 token 即可实现登出。
后端可以维护一个无效 token 列表来增强安全性。
有状态的认证(Stateful Authentication)是一种传统的认证方式,与无状态认证(如 JWT)相比,它在服务器端维护用户的会话状态。以下是有状态认证的典型流程:
- 登录阶段:
用户通过前端输入用户名和密码。
前端将这些凭证发送到后端服务器。
后端验证用户名和密码。
会话创建:
如果验证成功,服务器创建一个会话(Session)。
服务器生成一个唯一的会话 ID。
服务器将用户信息存储在服务器端,与会话 ID 关联。
- 返回会话标识:
服务器将会话 ID 返回给客户端。
通常,这个会话 ID 会被设置为一个 cookie。
后续请求:
客户端在每次请求时都会自动发送包含会话 ID 的 cookie。
服务器接收到请求后,通过会话 ID 查找对应的会话信息。
服务器根据会话中存储的用户信息来验证和授权请求。
- 会话维护:
服务器需要持续维护所有活跃的会话。
会话通常有一个过期时间,超时后会被销毁。
用户活动可以刷新会话的过期时间。
- 登出:
用户登出时,服务器会销毁对应的会话。
客户端的会话 cookie 通常也会被删除。
React 中的 useRef 钩子
在 React 中,useRef 是一个钩子(Hook),它允许你在渲染之间持久地引用值。这个钩子非常有用,因为它可以用来存储不会引起组件重新渲染的可变值。useRef 通常用于两种主要情况:访问 DOM 节点和保留渲染之间的值。
使用 useRef 访问 DOM 节点
当你需要直接与 DOM 交互时,useRef 可以非常有用。例如,你可能想要在组件加载时自动聚焦到一个输入框,或者在某个动作发生时滚动到页面的特定部分。这里是一个使用 useRef 来聚焦输入框的例子:
1 | import { useRef } from 'react'; |
在这个例子中,我们创建了一个 ref 对象,并将其作为 ref 属性传递给 元素。当组件渲染后,React 会将 inputRef.current 设置为对应的 DOM 节点,这样我们就可以调用 DOM 节点上的 focus 方法了。
使用 useRef 保留值
useRef 还可以用来在组件的多次渲染之间保留数据。与状态(state)不同,更新 ref 的 current 属性不会触发组件的重新渲染,这使得它成为存储不需要渲染的信息的理想选择。以下是一个使用 useRef 跟踪组件渲染次数的例子:
1 | import { useState, useEffect, useRef } from 'react'; |
在这个例子中,我们使用 useRef 来创建一个 ref 对象 count,它的 current 属性被初始化为 0。每次组件渲染后,我们在 useEffect 钩子中更新 count.current,但这不会触发额外的渲染,因为 ref 的更新不会导致组件状态的变化。
useRef 的注意事项
- 可变性:useRef 返回的对象是可变的,即你可以随时更改 current 属性,但这不会引起组件的重新渲染。
- 不触发重新渲染:当你改变 ref.current 时,React 不会意识到这一变化,因此不会重新渲染组件。
- 不要在渲染期间修改:除了初始化之外,不要在组件渲染期间读取或写入 ref.current,这会使组件的行为变得不可预测。
总的来说,useRef 是 React 中一个非常有用的钩子,它提供了一种在组件的整个生命周期中保留数据的方式,而不会影响组件的渲染行为。无论是直接操作 DOM,还是在渲染之间保留数据,useRef 都是一个值得掌握的工具。
git: error: RPC failed; HTTP 400 curl 22 The requested URL returned error: 400
非常好!看起来您已经成功解决了问题并成功推送了代码到您的新仓库。让我解释一下发生了什么:
- 初始错误:
最初,您遇到了 HTTP 400 错误,这可能是由于数据包大小限制导致的。 - 解决方案:
您使用了以下命令增加了 Git 的 HTTP post 缓冲区大小:
1 | git config --global http.postBuffer 524288000 |
这将 post 缓冲区大小设置为约 500MB,这通常足以处理大多数仓库。
- 成功推送:
增加缓冲区大小后,您再次尝试推送,这次成功了:
1 | git push -u origin master |
- 推送结果:
- 所有对象都被成功枚举、计数、压缩和写入。
- 总共推送了 1484 个对象,其中包括 735 个 delta。
- 新分支
master被创建并推送到远程仓库。 - 本地
master分支被设置为跟踪远程的origin/master。
- 重要的输出行:
1 | To https://github.com/gyc-12/license-gyc-frontend.git |
这表明推送成功,并且您的本地 master 分支现在与远程的 origin/master 关联。
现在,您的代码已经成功上传到您的 GitHub 仓库。您可以在 GitHub 网站上查看您的仓库,应该能看到所有推送的文件和提交历史。
接下来的步骤:
- 验证:在 GitHub 上检查您的仓库,确保所有文件都已正确上传。
- 继续开发:您现在可以正常进行开发,使用
git push推送新的更改。 - 协作:如果有其他开发者,他们现在可以克隆您的仓库并开始协作。
- 分支管理:考虑创建其他分支进行功能开发或 bug 修复。
- 保护设置:在 GitHub 仓库设置中,考虑设置分支保护规则,特别是对
master分支。
恭喜您成功解决了这个问题!
我更愿意用非对称加密这种叫法。因为可以体现出加密和解密使用不同的密钥
对称加密中,我们只需要一个密钥,通信双方同时持有。而非对称加密需要4个密钥。通信双方各自准备一对公钥和私钥。其中公钥是公开的,由信息接受方提供给信息发送方。公钥用来对信息加密。私钥由信息接受方保留,用来解密。既然公钥是公开的,就不存在保密问题。也就是说非对称加密完全不存在密钥配送问题!你看,是不是完美解决了密钥配送问题?
回到刚才的例子,小明和下红经过研究发现非对称加密能解决他们通信的安全问题,于是做了下面的事情:
1、小明确定了自己的私钥 mPrivateKey,公钥 mPublicKey。自己保留私钥,将公钥mPublicKey发给了小红
2、小红确定了自己的私钥 hPrivateKey,公钥 hPublicKey。自己保留私钥,将公钥 hPublicKey 发给了小明
3、小明发送信息 “周六早10点soho T1楼下见”,并且用小红的公钥 hPublicKey 进行加密。
4、小红收到信息后用自己的私钥 hPrivateKey 进行解密。然后回复 “收到,不要迟到” 并用小明的公钥mPublicKey加密。
5、小明收到信息后用自己的私钥 mPrivateKey 进行解密。读取信息后心里暗想:还提醒我不迟到?每次迟到的都是你吧?
以上过程是一次完整的request和response。通过这个例子我们梳理出一次信息传输的非对称加、解密过程:
1、消息接收方准备好公钥和私钥
2、私钥接收方自己留存、公钥发布给消息发送方
3、消息发送方使用接收方公钥对消息进行加密
4、消息接收方用自己的私钥对消息解密
公钥只能用做数据加密。公钥加密的数据,只能用对应的私钥才能解密。这是非对称加密的核心概念。
下面我用一个更为形象的例子来帮助大家理解。
我有下图这样一个信箱。
由于我只想接收我期望与之通信的朋友信件。于是我在投递口加了一把锁,这把锁的钥匙(公钥)我可以复制n份,发给我想接受其信件的人。只有这些人可以用这把钥匙打开寄信口,把信件投入。
收信门是另外一把锁,打开后可以拿出所有的信件。寄信口的钥匙并不能打开这把锁。这把锁的钥匙(私钥)当然只有我有。我可以用这把钥匙打开信箱门,取出所有发给我的信件。
相信通过这个例子,可以帮助大家彻底理解公钥和私钥的概念。
数字签名
数字签名是基于公钥密码体制的一种技术,用于验证数据的完整性和身份的真实性。它通过以下三个基本特征来实现:
报文鉴别:接收者能够核实发送者对报文的签名;
报文的完整性:接收者不能伪造对报文的签名或更改报文内容;
不可否认性:发送者事后不能抵赖对报文的签名。
数字签名通常包括以下几个步骤:
计算摘要:发送方用哈希算法生成报文的摘要;
摘要加密:发送方用自己的私钥对摘要进行加密,形成数字签名;
摘要验证:接收方用发送方的公钥对签名进行解密,得到摘要,并用同样的哈希算法重新生成摘要进行比对,以验证报文的完整性和真实性。
数字签名广泛应用于以下场景:
电子邮件:用于验证邮件发送者的身份;
电子合同:用于证明合同的签署者身份和合同内容;
电子发票:用于验证发票的真实性和完整性
您提出了一个非常好的问题,这有助于我们更全面地理解数字签名的工作原理。让我详细解释一下整个过程:
- 消息传输和数字签名是分开的两个过程:a. 消息传输:
b. 数字签名:
- 明文消息通常是直接传输的,或者使用对称加密算法加密后传输。
- 如果需要保密,可以使用接收方的公钥加密消息(这是标准的RSA加密过程,不是签名过程)。
- 数字签名只用于验证消息的完整性和发送者的身份,不用于加密整个消息。
- 完整的过程通常如下:发送方:
接收方:
1. 准备要发送的明文消息。
2. 计算消息的哈希值(摘要)。
3. 用私钥加密哈希值,生成数字签名。
4. 将原始消息和数字签名一起发送。
5. 接收原始消息和数字签名。
6. 使用相同的哈希算法计算接收到的消息的哈希值。
7. 用发送方的公钥解密数字签名,得到原始的哈希值。
8. 比较计算得到的哈希值和解密得到的哈希值。
- 实际传输示例:
1 | [原始消息] + [数字签名] |
例如:
1 | "Hello, World!" + "encrypted_hash_value" |
- 如果需要保密:可以将整个包(消息+签名)用接收方的公钥加密,或使用对称加密算法(如AES)加密。
- 为什么这样做:
- 效率:直接对整个消息进行私钥加密会非常慢,特别是对于大型消息。
- 验证目的:数字签名的主要目的是验证消息的完整性和发送者的身份,而不是保密。
- 安全性:
- 即使攻击者截获了消息和签名,也无法伪造有效的签名,因为他们没有私钥。
- 如果消息被篡改,重新计算的哈希值将与签名中的哈希值不匹配。
总结:
数字签名机制允许明文消息和签名一起传输。签名本身不加密消息,而是提供了一种验证消息完整性和发送者身份的方法。如果需要保密,可以在这个过程之上添加额外的加密层。这种方法既保证了安全性,又保持了效率。
加密方式
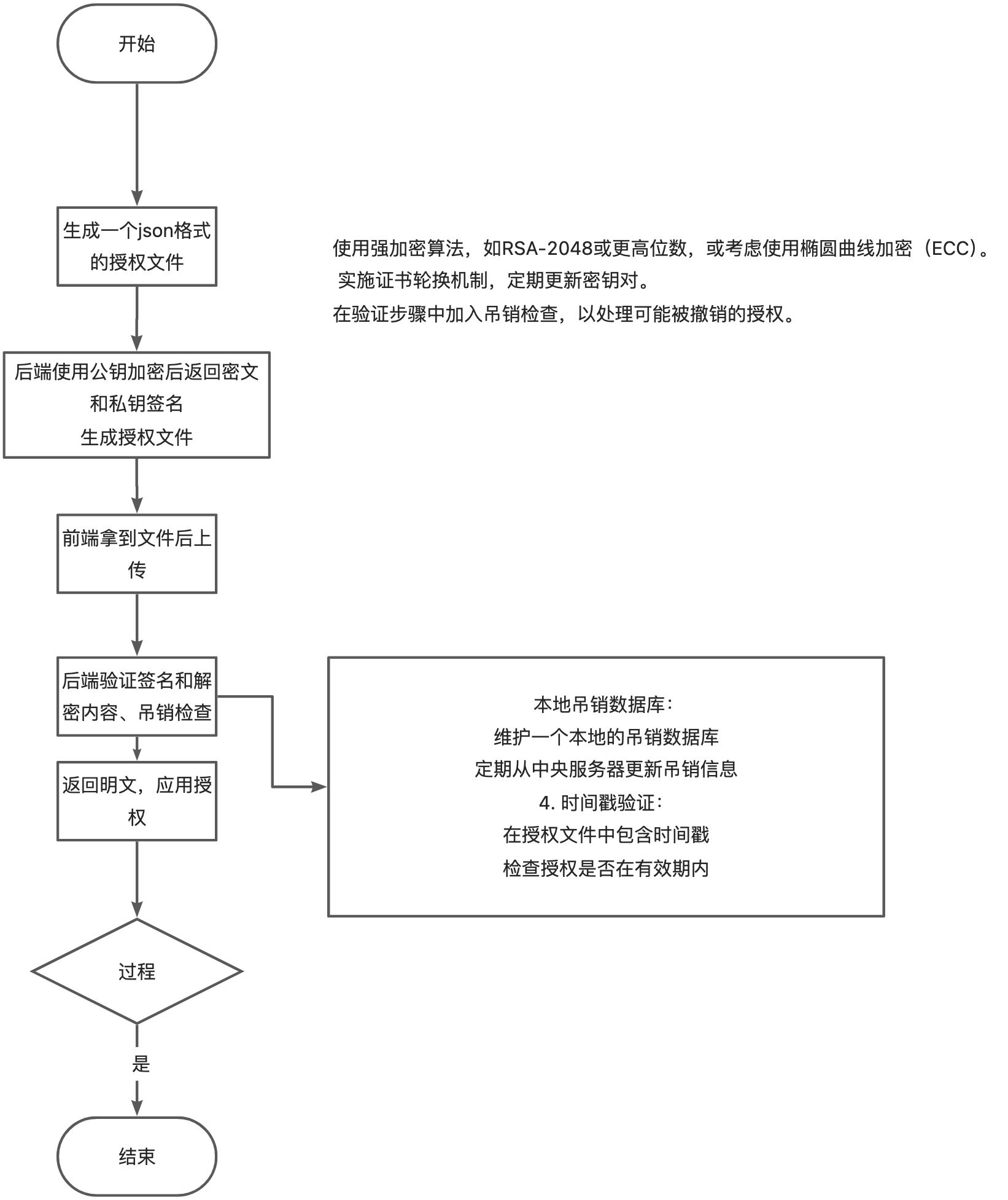
- 公钥加密,私钥解密:
这是最常见的用法,用于保护数据的机密性。
任何人都可以使用公钥加密数据,但只有拥有私钥的人才能解密。 - 私钥签名,公钥验证:
这用于数字签名,确保数据的完整性和来源。
私钥持有者使用私钥”签名”数据,任何拥有公钥的人都可以验证签名的真实性。
在 RSA 中,私钥确实可以用来”加密”数据,但这实际上是在创建数字签名。公钥可以用来验证这个签名,但这个过程通常不被称为”解密”。 - 后端使用公钥加密信息:
正确。这确保只有拥有私钥的人(通常是客户端)能解密信息。
生成私钥签名:
正确。后端使用私钥对原始信息(未加密的)进行签名,而不是对加密后的密文签名。
将密文和签名一起放入文件:
正确。这样可以同时实现加密(保护机密性)和签名(确保完整性和真实性)。
完整的流程应该是这样的:
后端准备要发送的原始信息。
使用公钥加密这个信息,得到密文。
使用私钥对原始信息(未加密的)进行签名,得到数字签名。
将密文、数字签名,可能还有一些元数据(如使用的算法、时间戳等)一起打包到一个文件或数据结构中。
接收方(通常是客户端)在收到这个文件后: - 使用私钥解密密文,获得原始信息。
使用公钥验证数字签名,确认信息的完整性和来源。
这种方法确实同时实现了加密和签名,提供了很好的安全保障。您的理解基本正确,只需要注意签名是对原始信息进行的,而不是对加密后的密文。
Context 的使用场景
- 主题: 如果你的应用允许用户更改其外观(例如暗夜模式),你可以在应用顶层放一个 context provider,并在需要调整其外观的组件中使用该 context。
- 当前账户: 许多组件可能需要知道当前登录的用户信息。将它放到 context 中可以方便地在树中的任何位置读取它。某些应用还允许你同时操作多个账户(例如,以不同用户的身份发表评论)。在这些情况下,将 UI 的一部分包裹到具有不同账户数据的 provider 中会很方便。
- 路由: 大多数路由解决方案在其内部使用 context 来保存当前路由。这就是每个链接“知道”它是否处于活动状态的方式。如果你创建自己的路由库,你可能也会这么做。
- 状态管理: 随着你的应用的增长,最终在靠近应用顶部的位置可能会有很多 state。许多遥远的下层组件可能想要修改它们。通常 将 reducer 与 context 搭配使用来管理复杂的状态并将其传递给深层的组件来避免过多的麻烦。
Context 不局限于静态值。如果你在下一次渲染时传递不同的值,React 将会更新读取它的所有下层组件!这就是 context 经常和 state 结合使用的原因。
一般而言,如果树中不同部分的远距离组件需要某些信息,context 将会对你大有帮助。
步骤
- Context 使组件向其下方的整个树提供信息。
- 传递 Context 的方法:
- 通过
export const MyContext = createContext(defaultValue)创建并导出 context。 - 在无论层级多深的任何子组件中,把 context 传递给
useContext(MyContext)Hook 来读取它。 - 在父组件中把 children 包在
<MyContext.Provider value={...}>中来提供 context。
- 通过
- Context 会穿过中间的任何组件。
- Context 可以让你写出 “较为通用” 的组件。
- 在使用 context 之前,先试试传递 props 或者将 JSX 作为
children传递。
Kubernetes 为你提供:
- 服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来暴露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
- 存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
- 自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
- 自动完成装箱计算
你为 Kubernetes 提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。 Kubernetes 可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。
- 自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。
- 密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
- 批处理执行 除了服务外,Kubernetes 还可以管理你的批处理和 CI(持续集成)工作负载,如有需要,可以替换失败的容器。
- 水平扩缩 使用简单的命令、用户界面或根据 CPU 使用率自动对你的应用进行扩缩。
- IPv4/IPv6 双栈 为 Pod(容器组)和 Service(服务)分配 IPv4 和 IPv6 地址。
- 为可扩展性设计 在不改变上游源代码的情况下为你的 Kubernetes 集群添加功能。
来自: 概述 | Kubernetes
要区别:
职责不同:
Controller负责处理HTTP请求和响应。
Service负责实现业务逻辑。
2. 位置不同:
Controller在MVC架构中属于表现层。
Service属于业务逻辑层。
依赖关系:
Controller通常依赖于Service。
Service可能依赖于Repository或其他Service。
复用性:
Service更容易被多个Controller复用。
Controller通常与特定的URL路径绑定。
测试方式:
Controller测试通常涉及模拟HTTP请求。
Service测试更关注业务逻辑的正确性。
这种分层设计有助于保持代码的清晰和模块化,使得系统更易于维护和扩展。
- Title: 无标题文档
- Author: gaoyanchen
- Created at : 2024-11-11 21:02:00
- Updated at : 2024-11-11 21:03:18
- Link: https://gyc.660624.xyz/2024/11/11/无标题文档_sxi913pw50k56nkw/
- License: This work is licensed under CC BY-NC-SA 4.0.